Action-Grounded Surface Geometry and Volumetric Shape Feature Representations for Object Affordance Prediction
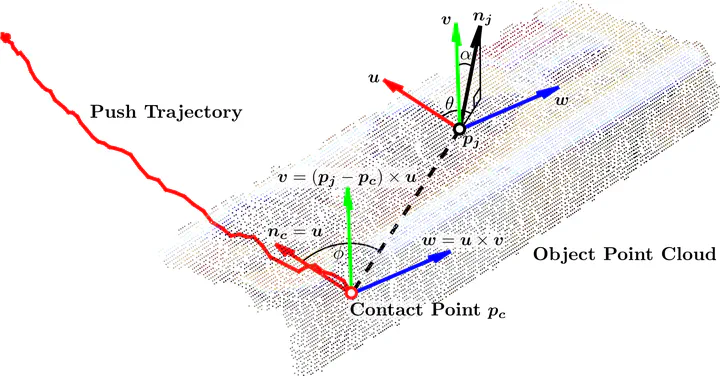 Action-grounded Darboux frame construction example for the shape component of AGVFH.
Action-grounded Darboux frame construction example for the shape component of AGVFH.Abstract
Many 3D feature descriptors have been developed over the years to solve problems that require the representation of object shape, e. g. object recognition or pose estimation, but comparatively few have been developed specifically to tackle the problem of object affordance learning, a domain where the interaction between action parameters and sensory features play a crucial role. In previous work, we introduced a feature descriptor that divided an object point cloud into coarse-grained cells, derived simple features from each of the cells, and grounded those features with respect to a reference frame defined by a pushing action. We also compared this action-grounded descriptor to an equivalent non-action-grounded descriptor coupled with action features in a push affordance classification task and established that the action-grounded encoding can provide improved performance. In this paper, we investigate modifying more well-established 3D shape descriptors based on surface geometry, in particular the Viewpoint Feature Histogram (VFH), such that they are action-grounded in a similar manner, compare them to volumetric octree-based representations, and conclude that having multi-scaled representations in which parts at each scale can be referenced with respect to each other may be a crucial component in action-grounded affordance learning.
Type
Publication
2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids)